
Responsa: la piattaforma di ChatBot che supporta i tuoi utenti in tutta autonomia, integrandosi naturalmente con i tuoi ecosistemi aziendali.
Unisciti anche tu alle aziende che hanno scelto Responsa
Supporta, coinvolgi, converti
SETTORI DI APPLICAZIONE
Affidati a Responsa
Scopri la piattaforma ChatBot di Responsa.
Grazie all’expertise ottenuta in diversi mercati, é in grado di dialogare e sopportare i tuoi utenti in modo naturale, immediato e semplice.
I nostri ChatBot “pre allenati” e facilmente configurabili sulle principali esigenze del tuoi clienti o dipendenti, ti permetteranno di ottenere il massimo dalla tua industry.

I vantaggi di Responsa
Risponde in un lampo
Un Assistente Virtuale disponibile in ogni momento per il Customer Care e la Shopping Experience di nuova generazione.
Si installa in 1 minuto
Copia e incolla poche righe di codice e in un minuto sei pronto a partire. L’integrazione base di Responsa richiede il semplice copia-incolla di poche righe di codice JavaScript!
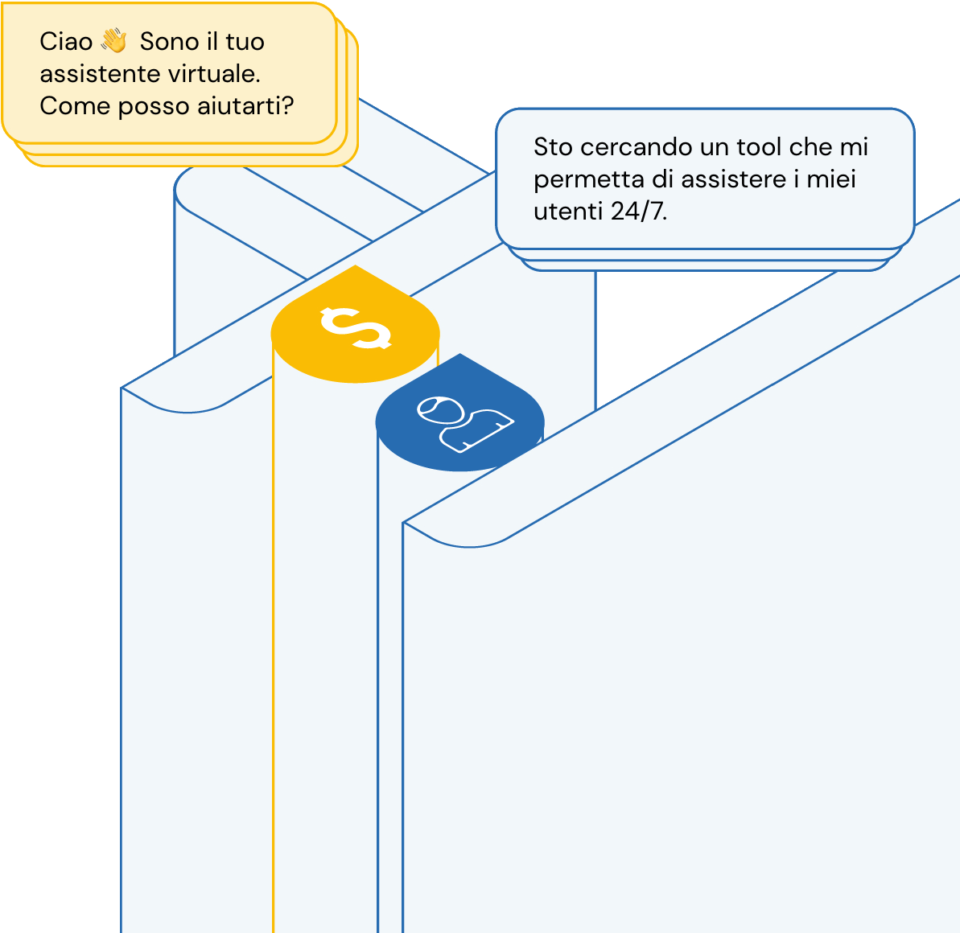
Supporta gli utenti 24/7
Il ChatBot Responsa utilizza intelligenza artificiale e machine learning per soddisfare le domande dei tuoi utenti automaticamente, in tempo reale, H24 e 7 giorni su 7.
Per i tuoi clienti
- Aumenta il Conversion Rate
- Riduci i costi di Customer Care
- Diminuisci il traffico in-bound
- Raccogli insights sugli utenti
Per i tuoi dipendenti
- Capitalizza e condividi il knowhow
- Facilita training e onboarding
- Riduci i tempi di accesso alle informazioni
- Migliora l'efficienza dei dipendenti
I nostri casi studio di successo
Scarica i report approfonditi per scoprire i vantaggi e i risultati ottenuti grazie a Responsa!
FUNZIONALITÀ
Ottieni il massimo da Responsa
Integrazioni
Totale integrazione con le principali piattaforme di mercato: fornisci un’automazione istantanea su tutti i canali.
Ricerca intelligente
L’algoritmo di ricerca semantica permette di trovare sempre il risultato migliore nel minor tempo possibile.
Riconoscimento vocale
Convertendo in tempo reale la voce in testo e viceversa, gli utenti possono interagire tramite l’interfaccia vocale.
Multilingua
Un chatbot in grado di funzionare efficacemente in tutte le lingue per fornire un totale supporto agli utenti.
Analytics
Responsa ti fornisce statistiche in tempo reale per permetterti di capire meglio i tuoi utenti.
Machine learning
Plugins
Responsa si integra con gli strumenti che già utilizzi per ottenere il massimo dai dati dei tuoi clienti.
Comunica con i tuoi clienti sull’app di instant messaging più popolare e amata al mondo.
La piattaforma di Chatbot e Conversational AI per ridurre i costi e aumentare le vendite
Migliora il tuo business, ora!





